

Amazon SageMaker Lakehouse is a unified, open, and safe knowledge lakehouse that now seamlessly integrates with Amazon S3 Tables, the primary cloud object retailer with built-in Apache Iceberg assist. With this integration, SageMaker Lakehouse supplies unified entry to S3 Tables, common function Amazon S3 buckets, Amazon Redshift knowledge warehouses, and knowledge sources akin to Amazon DynamoDB or PostgreSQL. You possibly can then question, analyze, and be a part of the information utilizing Redshift, Amazon Athena, Amazon EMR, and AWS Glue. Along with your acquainted AWS providers, you may entry and question your knowledge in-place along with your selection of Iceberg-compatible instruments and engines, offering you the flexibleness to make use of SQL or Spark-based instruments and collaborate on this knowledge the best way you want. You possibly can safe and centrally handle your knowledge within the lakehouse by defining fine-grained permissions with AWS Lake Formation which can be constantly utilized throughout all analytics and machine studying(ML) instruments and engines.
Organizations have gotten more and more knowledge pushed, and as knowledge turns into a differentiator in enterprise, organizations want sooner entry to all their knowledge in all areas, utilizing most popular engines to assist quickly increasing analytics and AI/ML use instances. Let’s take an instance of a retail firm that began by storing their buyer gross sales and churn knowledge of their knowledge warehouse for enterprise intelligence experiences. With large development in enterprise, they should handle a wide range of knowledge sources in addition to exponential development in knowledge quantity. The corporate builds an information lake utilizing Apache Iceberg to retailer new knowledge akin to buyer critiques and social media interactions.
This allows them to cater to their finish clients with new personalised advertising campaigns and perceive its influence on gross sales and churn. Nonetheless, knowledge distributed throughout knowledge lakes and warehouses limits their means to maneuver rapidly, as it could require them to arrange specialised connectors, handle a number of entry insurance policies, and infrequently resort to copying knowledge, that may improve price in each managing the separate datasets in addition to redundant knowledge saved. SageMaker Lakehouse addresses these challenges by offering safe and centralized administration of information in knowledge lakes, knowledge warehouses, and knowledge sources akin to MySQL, and SQL Server by defining fine-grained permissions which can be constantly utilized throughout knowledge in all analytics engines.
On this put up, we information you find out how to use varied analytics providers utilizing the combination of SageMaker Lakehouse with S3 Tables. We start by enabling integration of S3 Tables with AWS analytics providers. We create S3 Tables and Redshift tables and populate them with knowledge. We then arrange SageMaker Unified Studio by creating an organization particular area, new venture with customers, and fine-grained permissions. This lets us unify knowledge lakes and knowledge warehouses and use them with analytics providers akin to Athena, Redshift, Glue, and EMR.
Answer overview
As an example the answer, we’re going to contemplate a fictional firm known as Instance Retail Corp. Instance Retail’s management is enthusiastic about understanding buyer and enterprise insights throughout 1000’s of buyer touchpoints for hundreds of thousands of their clients that can assist them construct gross sales, advertising, and funding plans. Management needs to conduct an evaluation throughout all their knowledge to determine at-risk clients, perceive influence of personalised advertising campaigns on buyer churn, and develop focused retention and gross sales methods.
Alice is an information administrator in Instance Retail Corp who has launched into an initiative to consolidate buyer info from a number of touchpoints, together with social media, gross sales, and assist requests. She decides to make use of S3 Tables with Iceberg transactional functionality to attain scalability as updates are streamed throughout billions of buyer interactions, whereas offering similar sturdiness, availability, and efficiency traits that S3 is thought for. Alice already has constructed a big warehouse with Redshift, which incorporates historic and present knowledge about gross sales, clients prospects, and churn info.
Alice helps an prolonged staff of builders, engineers, and knowledge scientists who require entry to the information surroundings to develop enterprise insights, dashboards, ML fashions, and information bases. This staff consists of:
Bob, an information analyst who must entry to S3 Tables and warehouse knowledge to automate constructing buyer interactions development and churn throughout varied buyer touchpoints for every day experiences despatched to management.
Charlie, a Enterprise Intelligence analyst who’s tasked to construct interactive dashboards for funnel of buyer prospects and their conversions throughout a number of touchpoints and make these out there to 1000’s of Gross sales staff members.
Doug, an information engineer liable for constructing ML forecasting fashions for gross sales development utilizing the pipeline and/or buyer conversion throughout a number of touchpoints and make these out there to finance and planning groups.
Alice decides to make use of SageMaker Lakehouse to unify knowledge throughout S3 Tables and Redshift knowledge warehouse. Bob is happy about this choice as he can now construct every day experiences utilizing his experience with Athena. Charlie now is aware of that he can rapidly construct Amazon QuickSight dashboards with queries which can be optimized utilizing Redshift’s cost-based optimizer. Doug, being an open supply Apache Spark contributor, is happy that he can construct Spark primarily based processing with AWS Glue or Amazon EMR to construct ML forecasting fashions.
The next diagram illustrates the answer structure.
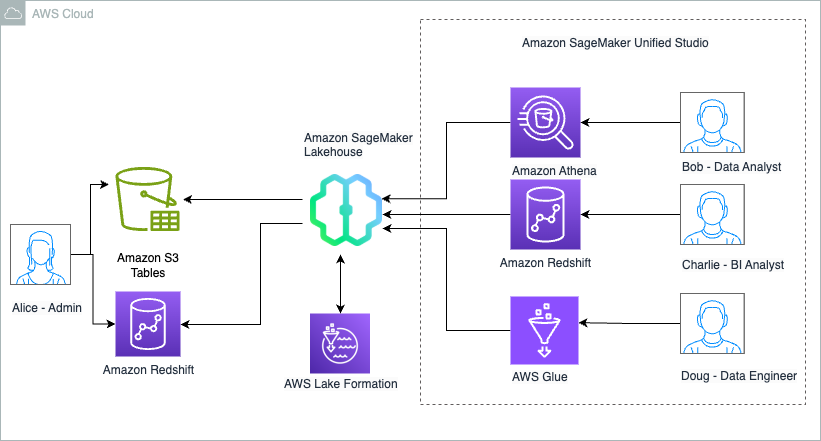
Implementing this resolution consists of the next high-level steps. For Instance Retail, Alice as an information Administrator performs these steps:
- Create a desk bucket. S3 Tables shops Apache Iceberg tables as S3 assets, and buyer particulars are managed in S3 Tables. You possibly can then allow integration with AWS analytics providers, which robotically units up the SageMaker Lakehouse integration in order that the tables bucket is proven as a baby catalog underneath the federated
s3tablescatalogwithin the AWS Glue Information Catalog and is registered with AWS Lake Formation for entry management. Subsequent, you create a desk namespace or database which is a logical assemble that you just group tables underneath and create a desk utilizing Athena SQL CREATE TABLE assertion. - Publish your knowledge warehouse to Glue Information Catalog. Churn knowledge is managed in a Redshift knowledge warehouse, which is revealed to the Information Catalog as a federated catalog and is obtainable in SageMaker Lakehouse.
- Create a SageMaker Unified Studio venture. SageMaker Unified Studio integrates with SageMaker Lakehouse and simplifies analytics and AI with a unified expertise. Begin by creating a site and including all customers (Bob, Charlie, Doug). Then create a venture within the area, selecting venture profile that provisions varied assets and the venture AWS Identification and Entry Administration (IAM) position that manages useful resource entry. Alice provides Bob, Charlie, and Doug to the venture as members.
- Onboard S3 Tables and Redshift tables to SageMaker Unified Studio. To onboard the S3 Tables to the venture, in Lake Formation, you grant permission on the useful resource to the SageMaker Unified Studio venture position. This allows the catalog to be discoverable throughout the lakehouse knowledge explorer for customers (Bob, Charlie, and Doug) to start out querying tables .SageMaker Lakehouse assets can now be accessed from computes like Athena, Redshift, and Apache Spark primarily based computes like Glue to derive churn evaluation insights, with Lake Formation managing the information permissions.
Conditions
To observe the steps on this put up, it’s essential to full the next conditions:
Alice completes the next steps to create the S3 Desk bucket for the brand new knowledge she plans so as to add/import into an S3 Desk.
- AWS account with entry to the next AWS providers:
- Amazon S3 together with S3 Tables
- Amazon Redshift
- AWS Identification and Entry Administration (IAM)
- Amazon SageMaker Unified Studio
- AWS Lake Formation and AWS Glue Information Catalog
- AWS Glue
- Create a person with administrative entry.
- Have entry to an IAM position that could be a Lake Formation knowledge lake administrator. For directions, check with Create an information lake administrator.
- Allow AWS IAM Identification Middle in the identical AWS Area the place you wish to create your SageMaker Unified Studio area. Arrange your id supplier (IdP) and synchronize identities and teams with AWS IAM Identification Middle. For extra info, check with IAM Identification Middle Identification supply tutorials.
- Create a read-only administrator position to find the Amazon Redshift federated catalogs within the Information Catalog. For directions, check with Conditions for managing Amazon Redshift namespaces within the AWS Glue Information Catalog.
- Create an IAM position named
DataTransferRole. For directions, check with Conditions for managing Amazon Redshift namespaces within the AWS Glue Information Catalog. - Create an Amazon Redshift Serverless namespace known as
churnwg. For extra info, see Get began with Amazon Redshift Serverless knowledge warehouses.
Create a desk bucket and allow integration with analytics providers
Alice completes the next steps to create the S3 Desk bucket for the brand new knowledge she plans so as to add/import into an S3 Tables.
Observe the under steps to create a desk bucket to allow integration with SageMaker Lakehouse:
- Register to the S3 console as person created in prerequisite step 2.
- Select Desk buckets within the navigation pane and select Allow integration.

- Select Desk buckets within the navigation pane and select Create desk bucket.
- For Desk bucket title, enter a reputation akin to
blog-customer-bucket. - Select Create desk bucket.

- Select Create desk with Athena.
- Choose Create a namespace and supply a namespace (for instance,
customernamespace). - Select Create namespace.

- Select Create desk with Athena.
- On the Athena console, run the next SQL script to create a desk:
That is simply an instance of including a number of rows to the desk, however usually for manufacturing use instances, clients use engines akin to Spark so as to add knowledge to the desk.
S3 Tables buyer is now created, populated with knowledge and built-in with SageMaker Lakehouse.
Arrange Redshift tables and publish to the Information Catalog
Alice completes the next steps to attach the information in Redshift to be revealed into the information catalog. We’ll additionally display how the Redshift desk is created and populated, however in Alice’s case Redshift desk already exists with all of the historic knowledge on gross sales income.
- Register to the Redshift endpoint
churnwgas an admin person. - Run the next script to create a desk underneath the
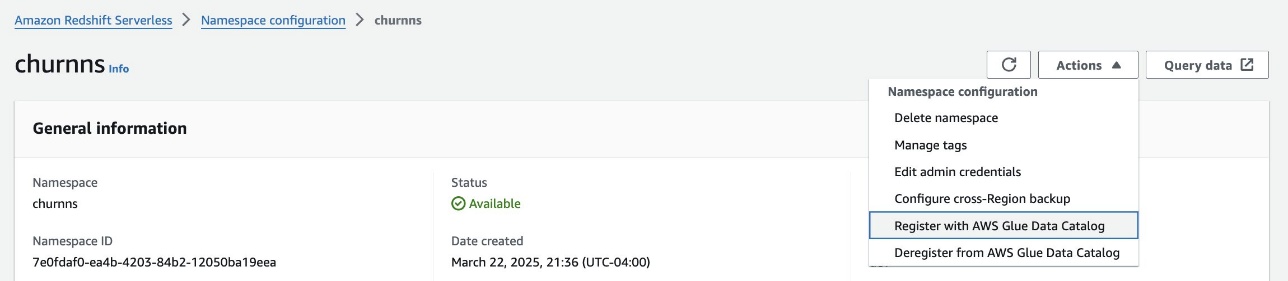
devdatabase underneath the general public schema: - On the Redshift Serverless console, navigate to the namespace.
- On the Motion dropdown menu, select Register with AWS Glue Information Catalog to combine with SageMaker Lakehouse.
- Select Register.
- Register to the Lake Formation console as the information lake administrator.
- Underneath Information Catalog within the navigation pane, select Catalogs and Pending catalog invites.
- Choose the pending invitation and select Approve and create catalog.

- Present a reputation for the catalog (for instance,
churn_lakehouse). - Underneath Entry from engines, choose Entry this catalog from Iceberg-compatible engines and select
DataTransferRolefor the IAM position. - Select Subsequent.
- Select Add permissions.
- Underneath Principals, select the
datalakeadminposition for IAM customers and roles, Tremendous person for Catalog permissions, and select Add. - Select Create catalog.
Redshift Desk customer_churn is now created, populated with knowledge and built-in with SageMaker Lakehouse.
Create a SageMaker Unified Studio area and venture
Alice now units up SageMaker Unified Studio area and tasks in order that she will deliver customers (Bob, Charlie and Doug) collectively within the new venture.
Full the next steps to create a SageMaker area and venture utilizing SageMaker Unified Studio:
- On the SageMaker Unified Studio console, create a SageMaker Unified Studio area and venture utilizing the All Capabilities profile template. For extra particulars, check with Organising Amazon SageMaker Unified Studio. For this put up, we create a venture named
churn_analysis. - Setup AWS Identification middle with customers Bob, Charlie and Doug, Add them to area and venture.
- From SageMaker Unified Studio, navigate to the venture overview and on the Venture particulars tab, notice the venture position Amazon Useful resource Identify (ARN).

- Register to the IAM console as an admin person.
- Within the navigation pane, select Roles.
- Seek for the venture position and add AmazonS3TablesReadOnlyAccess by selecting Add permissions.
SageMaker Unified Studio is now setup with area, venture and customers.
Onboard S3 Tables and Redshift tables to the SageMaker Unified Studio venture
Alice now configures SageMaker Unified Studio venture position for fine-grained entry management to find out who on her staff will get to entry what knowledge units.
Grant the venture position full desk entry on buyer dataset. For that, full the next steps:
- Register to the Lake Formation console as the information lake administrator.
- Within the navigation pane, select Information lake permissions, then select Grant.
- Within the Principals part, for IAM customers and roles, select the venture position ARN famous earlier.
- Within the LF-Tags or catalog assets part, choose Named Information Catalog assets:
- Select
:s3tablescatalog/blog-customer-bucket - Select
customernamespacefor Databases. - Select buyer for Tables.
- Select
- Within the Desk permissions part, choose Choose and Describe for permissions.
- Select Grant.
Now grant the venture position entry to subset of columns from customer_churn dataset.
- Within the navigation pane, select Information lake permissions, then select Grant.
- Within the Principals part, for IAM customers and roles, select the venture position ARN famous earlier.
- Within the LF-Tags or catalog assets part, choose Named Information Catalog assets:
- Select
:churn_lakehouse/dev - Select public for Databases.
- Select
customer_churnfor Tables.
- Select
- Within the Desk Permissions part, choose Choose.
- Within the Information Permissions part, choose Column-based entry.
- For Select permission filter, choose Embody columns and select
customer_id,internet_service, andis_churned. - Select Grant.

All customers within the venture churn_analysis in SageMaker Unified Studio at the moment are setup. They’ve entry to all columns within the desk and fine-grained entry permissions for Redshift desk the place they’ve entry to solely three columns.
Confirm knowledge entry in SageMaker Unified Studio
Alice can now do a closing verification if the information is all out there to make sure that every of her staff members are set as much as entry the datasets.
Now you may confirm knowledge entry for various customers in SageMaker Unified Studio.
- Register to SageMaker Unified Studio as Bob and select the
churn_analysis - Navigate to the Information explorer to view
s3tablescatalogandchurn_lakehouseunderneath Lakehouse.

Information Analyst makes use of Athena for analyzing buyer churn
Bob, the information analyst can now logs into to the SageMaker Unified Studio, chooses the churn_analysis venture and navigates to the Construct choices and select Question Editor underneath Information Evaluation & Integration.

Bob chooses the connection as Athena (Lakehouse), the catalog as s3tablescatalog/blog-customer-bucket, and the database as customernamespace. And runs the next SQL to research the information for buyer churn:

Bob can now be a part of the information throughout S3 Tables and Redshift in Athena and now can proceed to construct full SQL analytics functionality to automate constructing buyer development and churn management every day experiences.
BI Analyst makes use of Redshift engine for analyzing buyer knowledge
Charlie, the BI Analyst can now logs into the SageMaker Unified Studio and chooses the churn_analysis venture. He navigates to the Construct choices and select Question Editor underneath Information Evaluation & Integration. He chooses the connection as Redshift (Lakehouse), Databases as dev, Schemas as public.

He then runs the observe SQL to carry out his particular evaluation.
 Charlie can now additional replace the SQL question and use it to energy QuickSight dashboards that may be shared with Gross sales staff members.
Charlie can now additional replace the SQL question and use it to energy QuickSight dashboards that may be shared with Gross sales staff members.
Information engineer makes use of AWS Glue Spark engine to course of buyer knowledge
Lastly, Doug logs in to SageMaker Unified Studio as Doug and chooses the churn_analysis venture to carry out his evaluation. He navigates to the Construct choices and select JupyterLab underneath IDE & Functions. He downloads the churn_analysis.ipynb pocket book and add it into the explorer. He then runs the cells by deciding on compute as venture.spark.compatibility.
He runs the next SQL to research the information for buyer churn:

Doug, now can use Spark SQL and begin processing knowledge from each S3 tables and Redshift tables and begin constructing forecasting fashions for buyer development and churn
Cleansing up
In case you carried out the instance and wish to take away the assets, full the next steps:
- Clear up S3 Tables assets:
- Clear up the Redshift knowledge assets:
- On the Lake Formation console, select Catalogs within the navigation pane.
- Delete the
churn_lakehousecatalog.
- Delete SageMaker venture, IAM roles, Glue assets, Athena workgroup, S3 buckets created for area.
- Delete SageMaker area and VPC created for the setup.
Conclusion
On this put up, we confirmed how you should use SageMaker Lakehouse to unify knowledge throughout S3 Tables and Redshift knowledge warehouses, which may help you construct highly effective analytics and AI/ML functions on a single copy of information. SageMaker Lakehouse provides you the flexibleness to entry and question your knowledge in-place with Iceberg-compatible instruments and engines. You possibly can safe your knowledge within the lakehouse by defining fine-grained permissions which can be enforced throughout analytics and ML instruments and engines.
For extra info, check with Tutorial: Getting began with S3 Tables, S3 Tables integration, and Connecting to the Information Catalog utilizing AWS Glue Iceberg REST endpoint. We encourage you to check out the S3 Tables integration with SageMaker Lakehouse integration and share your suggestions with us.
Concerning the authors
 Sandeep Adwankar is a Senior Technical Product Supervisor at AWS. Based mostly within the California Bay Space, he works with clients across the globe to translate enterprise and technical necessities into merchandise that allow clients to enhance how they handle, safe, and entry knowledge.
Sandeep Adwankar is a Senior Technical Product Supervisor at AWS. Based mostly within the California Bay Space, he works with clients across the globe to translate enterprise and technical necessities into merchandise that allow clients to enhance how they handle, safe, and entry knowledge.
 Srividya Parthasarathy is a Senior Huge Information Architect on the AWS Lake Formation staff. She works with the product staff and clients to construct sturdy options and options for his or her analytical knowledge platform. She enjoys constructing knowledge mesh options and sharing them with the group.
Srividya Parthasarathy is a Senior Huge Information Architect on the AWS Lake Formation staff. She works with the product staff and clients to construct sturdy options and options for his or her analytical knowledge platform. She enjoys constructing knowledge mesh options and sharing them with the group.
 Aditya Kalyanakrishnan is a Senior Product Supervisor on the Amazon S3 staff at AWS. He enjoys studying from clients about how they use Amazon S3 and serving to them scale efficiency. Adi’s primarily based in Seattle, and in his spare time enjoys climbing and sometimes brewing beer.
Aditya Kalyanakrishnan is a Senior Product Supervisor on the Amazon S3 staff at AWS. He enjoys studying from clients about how they use Amazon S3 and serving to them scale efficiency. Adi’s primarily based in Seattle, and in his spare time enjoys climbing and sometimes brewing beer.

{kind=link}