

Whereas serving to our prospects construct methods on AWS, we discovered that a lot of enterprise prospects who pay nice consideration to information safety and compliance, similar to B2C FinTech enterprises, construct data-sensitive functions on premises and use different functions on AWS to take benefit AWS managed companies. Utilizing AWS managed companies can vastly simplify every day operation and upkeep, in addition to enable you to obtain optimized useful resource utilization and efficiency.
This submit discusses a decoupled method of constructing a serverless information lakehouse utilizing AWS Cloud-centered companies, together with Amazon EMR Serverless, Amazon Athena, Amazon Easy Storage Service (Amazon S3), Apache DolphinScheduler (an open supply information job scheduler) in addition to PingCAP TiDB, a third-party information warehouse product that may be deployed both on premises or on the cloud or by way of a software program as a service (SaaS).
Answer overview
For our use case, an enterprise information warehouse with enterprise information is hosted on an on-premises TiDB platform, an AWS International Accomplice that can be out there on AWS by way of AWS Market.
The info is then processed by an Amazon EMR Serverless Job to realize information lakehouse tiering logic. Completely different tiering information are saved in separate S3 buckets or separate S3 prefixes beneath the identical S3 bucket. Usually, there are 4 layers when it comes to information warehouse design.
- Operational information retailer layer (ODS) – This layer shops uncooked information of the info warehouse
- Knowledge warehouse stage layer (DWS) – This layer is a brief staging space throughout the information warehousing structure the place information from numerous sources is loaded, cleaned, remodeled, and ready earlier than being loaded into the info warehouse database layer;
- Knowledge warehouse database layer (DWD) – This layer is the central repository in an information warehousing atmosphere the place information from numerous sources is built-in, remodeled, and saved in a structured format for analytical functions;
- Analytical information retailer (ADS) – This layer is a subset of the info warehousing that’s particularly designed and optimized for a specific enterprise perform, division, or analytical objective.
For this submit, we solely use ODS and ADS layers to exhibit the technical feasibility.
The schema of this information is managed by way of the AWS Glue Knowledge Catalog, and might be queried utilizing Athena. The EMR Serverless Jobs are orchestrated utilizing Apache DolphinScheduler deployed in cluster mode on Amazon Elasctic Compute Cloud (Amazon EC2) situations, with meta information saved in an Amazon Relational Database Service (Amazon RDS) for MySQL occasion.
Utilizing DolphinScheduler as the info lakehouse job orchestrator presents the next benefits:
- Its distributed structure permits for higher scalability, and the visible DAG designer makes workflow creation extra intuitive for staff members with various technical experience
- It supplies extra granular task-level controls and helps a wider vary of job sorts out-of-the-box, together with Spark, Flink, and machine studying (ML) workflows, with out requiring extra plugin installations;
- Its multi-tenancy function allows higher useful resource isolation and entry management throughout completely different groups inside a company.
Nevertheless, DolphinScheduler requires extra preliminary setup and upkeep effort, making it extra appropriate for organizations with robust DevOps capabilities and a need for full management over their workflow infrastructure.
The next diagram illustrates the answer structure.

Stipulations
It’s essential create an AWS account and arrange an AWS Id and Entry Administration (IAM) consumer as a prerequisite for the next implementation. Full the next steps:
For AWS account signing up, please comply with up the actions guided per web page hyperlink.
- Create an AWS account.
- Sign up to the account utilizing the foundation consumer for the primary time.
- One the IAM console, create an IAM consumer with
AdministratorAccessCoverage. - Use this IAM consumer to log in AWS Administration Console slightly the foundation consumer.
- On the IAM console, select Customers within the navigation pane.
- Navigate to your consumer, and on the Safety credentials tab, create an entry key.
- Retailer the entry key and secret key in a safe place and use them for additional API entry of the sources of this AWS account.
Arrange DolphinScheduler, IAM configuration, and the TiDB Cloud desk
On this part, we stroll by way of the steps to put in DolphinScheduler, full extra IAM configurations to allow the EMR Serverless job, and provision the TiDB Cloud desk.
Set up DolphinScheduler on an EC2 occasion with an RDS for MySQL occasion storing DolphinScheduler metadata. The manufacturing deployment mode of DolphinScheduler is cluster mode. On this weblog, we use pseudo cluster mode which has the identical set up steps as cluster mode, and will obtain useful resource financial system. We title the EC2 occasion ds-pseudo.
Make certain the inbound rule of the safety group hooked up to the EC2 occasion permits port 12345’s TCP visitors. Then full the next steps:
- Log in to Amazon EC2 as the foundation consumer, and set up
jvm:sudo dnf set up java-1.8.0-amazon-corretto java -version
- Change to
dir /usr/native/src:cd /usr/native/src - Set up Apache Zookeeper:
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz cd apache-zookeeper-3.8.0-bin/conf cp zoo_sample.cfg zoo.cfg cd .. nohup bin/zkServer.sh start-foreground &> nohup_zk.out & bin/zkServer.sh standing
- Examine the Python model:
python3 --versionThe model ought to be 3.9 or above. It is strongly recommended that you simply use Amazon Linux 2023 or later because the Amazon EC2 working system (OS); Python model 3.9 meets the requirement. For element info, discuss with Python in AL2023.

- Set up Dolphinscheduler
- Obtain the
dolphinschedulerbundle:cd /usr/native/src wget https://dlcdn.apache.org/dolphinscheduler/3.1.9/apache-dolphinscheduler-3.1.9-bin.tar.gz tar -zxvf apache-dolphinscheduler-3.1.9-bin.tar.gz mv apache-dolphinscheduler-3.1.9-bin apache-dolphinscheduler - Obtain the
mysqlconnector bundle:wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.0.31.tar.gz tar -zxvf mysql-connector-j-8.0.31.tar.gz - Copy particular
mysqlconnector JAR file to the next locations:cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler/api-server/libs/ cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler/alert-server/libs/ cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler/master-server/libs/ cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler/worker-server/libs/ cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler/instruments/libs/ - Add the consumer
dolphinscheduler, and ensure the listingapache-dolphinschedulerand the recordsdata beneath it are owned by the consumerdolphinscheduler:useradd dolphinscheduler echo "dolphinscheduler" | passwd --stdin dolphinscheduler sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /and many others/sudoers sed -i 's/Defaults requirett/#Defaults requirett/g' /and many others/sudoers chown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler
- Obtain the
- Set up the
mysqlshopper:sudo dnf replace -y sudo dnf set up mariadb105 - On the Amazon RDS console, provision an RDS for MySQL occasion with the next configurations:
- For Database Creation Methodology, choose Customary create.
- For Engine choices, select MySQL.
- For Version: select MySQL 8.0.35.
- For Templates: choose Dev/Take a look at.
- For Availability and sturdiness, choose Single DB occasion.
- For Credentials administration, choose Self-managed.
- For Connectivity, choose Connect with an EC2 compute useful resource, and select the EC2 occasion created earlier.
- For Database Authentication: select Password Authentication.
- Navigate to the
ds- mysqldatabase particulars web page, and beneath Connectivity & safety, copy the RDS for MySQL endpoint.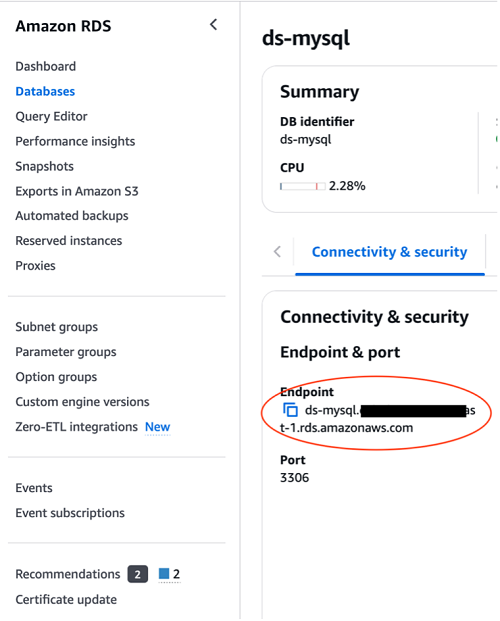
- Configure the intance:
mysql -h-u admin -p mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; mysql> exit; - Configure the
dolphinschedulerconfiguration file:cd /usr/native/src/apache-dolphinscheduler/ - Revise
dolphinscheduler_env.sh:vim bin/env/dolphinscheduler_env.sh export DATABASE=${DATABASE:-mysql} export SPRING_PROFILES_ACTIVE=${DATABASE} export SPRING_DATASOURCE_URL="jdbc:mysql://ds-mysql.cq**********.us-east-1.rds.amazonaws.com/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false" export SPRING_DATASOURCE_USERNAME="admin" export SPRING_DATASOURCE_PASSWORD="" - On the Amazon EC2 console, navigate to the occasion particulars web page and duplicate the personal IP handle.

- Revise
install_env.sh:vim bin/env/install_env.sh ips=${ips:-""} masters=${masters:-" "} employees=${employees:-" personal ip handle of ds-pseudo EC2 occasion:default"} alertServer=${alertServer:-" personal ip handle of ds-pseudo EC2 occasion "} apiServers=${apiServers:-" personal ip handle of ds-pseudo EC2 occasion "} installPath=${installPath:-"~/dolphinscheduler"} export JAVA_HOME=${JAVA_HOME:-/usr/lib/jvm/jre-1.8.0-openjdk} export PYTHON_HOME=${PYTHON_HOME:-/bin/python3} - Configure the
dolphinschedulerconfiguration file:cd /usr/native/src/apache-dolphinscheduler/ bash instruments/bin/upgrade-schema.sh - Set up DolphinScheduler:
cd /usr/native/src/apache-dolphinscheduler/ su dolphinscheduler bash ./bin/set up.sh - Begin DolphinScheduler after set up:
cd /usr/native/src/apache-dolphinscheduler/ su dolphinscheduler bash ./bin/start-all.sh - Open the DolphinScheduler console:
http://:12345/dolphinscheduler/ui/login 
After enter the preliminary username and password, press Login button to enter into the dashboard proven as under.
preliminary consumer/password admin/dolphinscheduler123
Configure IAM function to allow the EMR serverless job
The EMR serverless job function must have permission to entry a particular S3 bucket to learn job scripts and doubtlessly write outcomes, and now have permission to entry AWS Glue to learn the Knowledge Catalog which shops the tables’ meta information. For detailed steering, please discuss with Grant permission to make use of EMR Serverless or EMR Serverless Samples.
The next screenshot reveals the IAM function configured with the belief coverage hooked up.

The IAM function ought to have the next permissions insurance policies hooked up, as proven within the following screenshot.
Provision the TiDB Cloud desk
- To provision the TiDB Cloud desk, full the next steps:
- Register for TiDB Cloud.
- Create a serverless cluster, as proven within the following screenshot. For this submit, we title the cluster
Cluster0.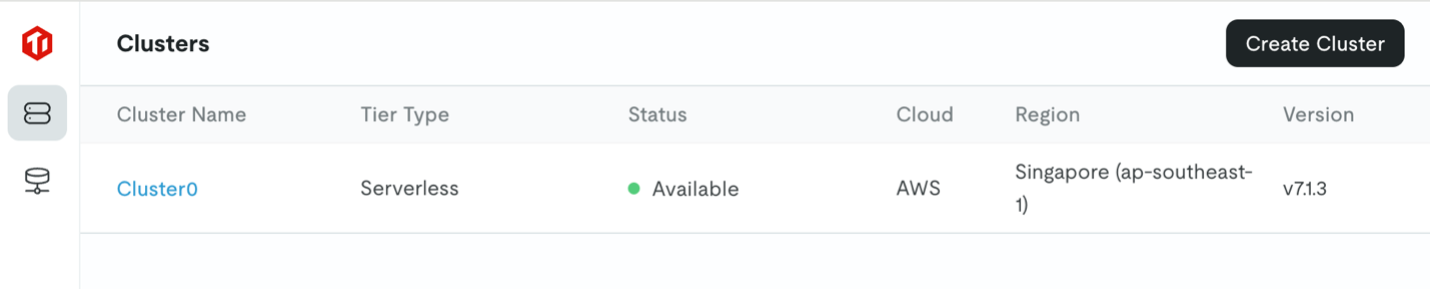
- Select
Cluster0, then select SQL Editor to create a database namedtake a look at:create desk testtable (id varchar(255)); insert into testtable values (1); insert into testtable values (2); insert into testtable values (3);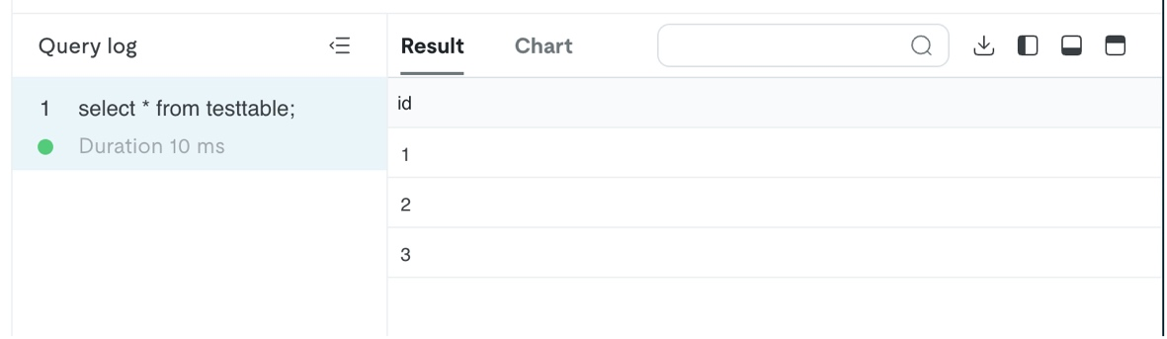
Synchronize information between on-premises TiDB and AWS
On this part, we talk about the best way to synchronize historic information in addition to incremental information between TiDB and AWS.
Use TiDB Dumpling to sync historic information from TiDB to Amazon S3
Use the instructions on this part to dump information saved in TiDB as CSV recordsdata right into a S3 bucket. For full particulars on the best way to obtain an information sync from on-premises TiDB to Amazon S3, see Export information to Amazon S3 cloud storage. For this submit, we use TiDB software Dumpling. Full the next steps:
- Log in to the EC2 occasion created earlier as root.
- Run the next command to put in TiUP:
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/set up.sh | sh cd /root supply .bash_profile tiup --version
- Run the next command to put in Dumpling:
tiup set up dumpling - Run the next command to realize goal database desk dumpling to the particular S3 bucket.
tiup dumpling -u-P 4000 -h -r 200000 -o "s3:// " --sql "choose * from . " --ca "/and many others/pki/tls/certs/ca-bundle.crt" --password - To amass the TiDB serverless connection info, navigate to the TiDB Cloud console and select Join.

You’ll be able to gather the particular connection info of take a look at database from the next screenshot.

Yan can view the info saved within the S3 bucket on the Amazon S3 console.

You should use Amazon S3 Choose to question the info and get outcomes just like the next screenshot, confirming that the info has been ingested into testtable.

Use TiDB Dumpling with a self-managed checkpoint to sync incremental information from TiDB to Amazon S3
To realize incremental information synchronization utilizing TiDB Dumpling, it’s important to self-manage the verify level of the goal synchronized information. One really helpful means is to retailer the ID of the ultimate ingested file right into a sure media (similar to Amazon ElastiCache for Redis, Amazon DynamoDB) to realize a self-managing checkpoint when operating the shell/Python job that trigges TiDB Dumpling. The prerequisite for implementing that is that the goal desk has a monotonically growing id area as its major key.
You should use the next TiDB Dumpling command to filter the exported information:
tiup dumpling -u . the place id > 2" --ca "/and many others/pki/tls/certs/ca-bundle.crt" --password Use the TiDB CDC connector to sync incremental information from TiDB to Amazon S3
The benefit of utilizing TiDB CDC connector to realize incremental information synchronization from TiDB to Amazon S3 is that there’s built-in change information seize (CDC) mechanism, and since the backend engine is Flink, the efficiency is quick. Nevertheless, there may be one trade-off: it is advisable to create a number of Flink tables to map the ODS tables on AWS.
For directions to implement the TiDB CDC connector, discuss with TiDB CDC.
Use an EMR serverless job to sync historic and incremental information from a Knowledge Catalog desk to the TiDB desk
Knowledge often flows from on premises to the AWS Cloud. Nevertheless, in some instances, the info would possibly stream from the AWS Cloud to your on-premises database.
After touchdown on AWS, the info can be wrapped up and managed by the Knowledge Catalog by created Athena tables with the particular tables’ schema. The desk DDL script is as follows:
CREATE EXTERNAL TABLE IF NOT EXISTS `testtable`(
`id` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
LOCATION 's3:/// /'; The screenshot under showcases the DDL operating outcome utilizing Athena console.

The info saved in testtable desk is queried utilizing choose * from testable SQL. The question result’s proven as follows:

On this case, an EMR serverless spark job can accomplish the work of synchronizing information from an AWS Glue desk to your on premises desk.
If the Spark job is written in Scala, the pattern code is as under:
bundle com.instance
import org.apache.spark.sql.{DataFrame, SparkSession}
object Most important {
def most important(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("")
.enableHiveSupport()
.getOrCreate()
spark.sql("present databases").present()
spark.sql("use default")
var df=spark.sql("choose * from testtable")
df.write
.format("jdbc")
.possibility("driver","com.mysql.cj.jdbc.Driver")
.possibility("url", "jdbc:mysql:// You’ll be able to purchase the TiDB serverless endpoint connection info on the TiDB console by selecting Join, as proven earlier on this submit.
After you may have wrapped the Scala code as JAR file utilizing SBT, you’ll be able to submit the job to EMR Serverless with the next AWS Command Line Interface (AWS CLI) command:
export applicationId=00fev6mdk***
export job_role_arn=arn:aws:iam:::function/emr-serverless-job-role
aws emr-serverless start-job-run
--application-id $applicationId
--execution-role-arn $job_role_arn
--job-driver '{
"sparkSubmit": {
"entryPoint": "",
"sparkSubmitParameters": "--conf spark.hadoop.hive.metastore.shopper.manufacturing facility.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.driver.cores=1 --conf spark.driver.reminiscence=3g --conf spark.executor.cores=4 --conf spark.executor.reminiscence=3g --jars s3://spark-sql-test-nov23rd/mysql-connector-j-8.2.0.jar"
}
}'
If the Spark job is written in PySpark, the pattern code is as follows:
import os
import sys
import pyspark.sql.capabilities as F
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession
.builder
.appName("app1")
.enableHiveSupport()
.getOrCreate()
df=spark.sql(f"choose * from {str(sys.argv[1])}")
df.write.format("jdbc").choices(
driver="com.mysql.cj.jdbc.Driver",
url="jdbc:mysql://tidbcloud_endpoint:4000/namespace ",
dbtable="table_name",
consumer="use_name",
password="password_string").save()
spark.cease()You’ll be able to submit the job to EMR Serverless utilizing the next AWS CLI command:
export applicationId=00fev6mdk***
export job_role_arn=arn:aws:iam:::function/emr-serverless-job-role
aws emr-serverless start-job-run
--application-id $applicationId
--execution-role-arn $job_role_arn
--job-driver '{
"sparkSubmit": {
"entryPoint": "",
"entryPointArguments": ["testspark"],
"sparkSubmitParameters": "--conf spark.hadoop.hive.metastore.shopper.manufacturing facility.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.driver.cores=1 --conf spark.driver.reminiscence=3g --conf spark.executor.cores=4 --conf spark.executor.reminiscence=3g --jars s3://spark-sql-test-nov23rd/mysql-connector-j-8.2.0.jar"
}
}' The previous PySpark code and AWS CLI command achieves outbound parameter enter as properly: the desk title (particularly testspark) is ingested into the SQL sentence when submitting the job.
EMR Serverless job pperation necessities
An EMR Serverless software is a useful resource pool idea. An software holds a sure capability of compute, reminiscence, and storage sources for jobs operating on it to make use of. You’ll be able to configure the useful resource capability utilizing AWS CLI or the console. As a result of it’s a useful resource pool, EMR Serverless software creation is often a one-time motion with the preliminary capability and most capability being configured.
An EMR Serverless job is a working unit that truly processes the compute job. To ensure that a job to work, it is advisable to set the EMR Serverless software ID, the execution IAM function (mentioned beforehand), and the particular software configuration (the sources the job is planning to make use of). Though you’ll be able to create the EMR Serverless job on the console, it’s really helpful to create the EMR Serverless job utilizing the AWS CLI for additional integration with the scheduler and scripts.
For extra particulars on EMR Serverless software creation and EMR Serverless job provisioning, discuss with EMR Serverless Hive question or EMR Serverless PySpark job
DolphinScheduler integration and job orchestration
DolphinScheduler is a contemporary information orchestration platform. It’s agile to create high- efficiency workflows with low code. It additionally supplies a robust UI, devoted to fixing advanced job dependencies within the information pipeline and offering numerous forms of jobs out of the field.
DolphinScheduler is developed and maintained by WhaleOps, and out there in AWS Market as WhaleStudio.
DolphinScheduler has been natively built-in with Hadoop: DolphinScheduler cluster mode is by default really helpful to be deployed on a Hadoop cluster (often on HDFS information nodes), and the HQL scripts uploaded to DolphinScheduler Useful resource Supervisor are saved by default on HDFS, and might be orchestrated utilizing the next native Hive shell command:
Hive -f instance.sqlFurthermore, for particular case wherein the orchestration DAGs are fairly sophisticated, every DAG consists of a number of jobs (for instance, greater than 300), and nearly all the roles are HQL scripts saved in DolphinScheduler Useful resource Supervisor.
Full the steps listed on this part to realize a seamless integration between DolphinScheduler and EMR Serverless.
Change the storage layer of DolphinScheduler Useful resource Heart from HDFS to Amazon S3
Edit the widespread.properties recordsdata beneath directories /usr/native/src/apache-dolphinscheduler/api-server/ and listing /usr/native/src/apache-dolphinscheduler/worker-server/conf. The next code snippet reveals the a part of the file that must be revised:
# useful resource storage sort: HDFS, S3, OSS, NONE
#useful resource.storage.sort=NONE
useful resource.storage.sort=S3
# useful resource retailer on HDFS/S3 path, useful resource file will retailer to this base path, self configuration, please ensure the listing exists on hdfs and have learn write permissions. "/dolphinscheduler" is really helpful
useful resource.storage.add.base.path=/dolphinscheduler
# The AWS entry key. if useful resource.storage.sort=S3 or use EMR-Job, This configuration is required
useful resource.aws.entry.key.id=AKIA************
# The AWS secret entry key. if useful resource.storage.sort=S3 or use EMR-Job, This configuration is required
useful resource.aws.secret.entry.key=lAm8R2TQzt*************
# The AWS Area to make use of. if useful resource.storage.sort=S3 or use EMR-Job, This configuration is required
useful resource.aws.area=us-east-1
# The title of the bucket. It's essential create them by your self. In any other case, the system can't begin. All buckets in Amazon S3 share a single namespace; make sure the bucket is given a singular title.
useful resource.aws.s3.bucket.title=dolphinscheduler-shiyang
# It's essential set this parameter when personal cloud s3. If S3 makes use of public cloud, you solely have to set useful resource.aws.area or set to the endpoint of a public cloud similar to S3.cn-north-1.amazonaws.com.cn
useful resource.aws.s3.endpoint=s3.us-east-1.amazonaws.comAfter modifying and saving the 2 recordsdata, restart the api-server and worker-server by operating the next instructions, beneath folder path /usr/native/src/apache-dolphinscheduler/
bash ./bin/stop-all.sh
bash ./bin/start-all.sh
bash ./bin/status-all.sh
You’ll be able to validate whether or not switching the storage layer to Amazon S3 was profitable by importing a script utilizing DolphinScheduler Useful resource Heart Console, verify if the file seems in related S3 bucket folder.
Earlier than verifying that Amazon S3 is now the storage location of DolphinScheduler, it is advisable to create a tenant on the DolphinScheduler console and bundle the admin consumer with the tenant, as illustrated within the following screenshots:


After that, you’ll be able to create a folder on the DolphinScheduler console, and verify whether or not the folder is seen on the Amazon S3 console.


Make certain the job scripts uploaded from Amazon S3 can be found within the DolphinScheduler Useful resource Heart
After engaging in the primary job, you’ll be able to add the scripts from the DolphinScheduler Useful resource Heart console, and make sure that the scripts are saved in Amazon S3. Nevertheless, in apply, it is advisable to migrate all scripts on to Amazon S3. You could find and modify the scripts saved in Amazon S3 utilizing DolphinScheduler Useful resource Heart console. To take action, you’ll be able to revise the metadata desk t_ds_resources by inserting all of the scripts’ metadata. The desk schema of desk t_ds_resources is proven within the following screenshot.

The insert command is as follows:
insert into t_ds_resources values(6, 'depend.java', ' depend.java','',1,1,0,'2024-11-09 04:46:44', '2024-11-09 04:46:44', -1, 'depend.java',0);Now there are two information within the desk t_ds_resoruces.

You’ll be able to entry related information on the DolphinScheduler console.

The next screenshot reveals the recordsdata on the Amazon S3 console.

Make the DolphinScheduler DAG orchestrator conscious of the roles’ standing so the DAG can transfer ahead or take related actions
As talked about earlier, DolphinScheduler is natively built-in with the Hadoop ecosystem, and the HQL scripts might be orchestrated by the DolphinScheduler DAG orchestrator through Hive -f xxx.sql command. In consequence, when the scripts modified to shell scripts or Python scripts (EMR Severless jobs must be orchestrated through shell scripts or Python scripts slightly than the straightforward Hive command), the DAG orchestrator can begin the job, however can’t get the actual time standing of the job, and subsequently can’t proceed the workflow to additional steps. As a result of the DAGs on this case are very sophisticated, it’s not possible to amend the DAGs; as an alternative we comply with a lift-and-shift technique.
We use the next scripts to seize jobs’ standing and take applicable actions.
Persist the appliance ID listing with the next code:
var=$(cat applicationlist.txt|grep appid1)
applicationId=${var#* }
echo $applicationIdAllow the DolphinScheduler step standing auto-check utilizing a Linux shell:
app_state
jq -r '.software')
state=$(echo $software
job_state
jq -r '.jobRun')
JOB_RUN_ID=$(echo $jobRun
state=$(job_state)
whereas [ $state != "SUCCESS" ]; do
case $state in
RUNNING)
state=$(job_state)
;;
SCHEDULED)
state=$(job_state)
;;
PENDING)
state=$(job_state)
;;
FAILED)
break
;;
esac
performed
if [ $state == "FAILED" ]
then
false
else
true
fiClear up
To wash up your sources, we advocate utilizing APIs by way of the next steps:
- Delete the EC2 occasion:
- Discover the occasion utilizing the next command:
aws ec2 describe-instances - Delete the occasion utilizing the next command:
aws ec2 terminate-instances –instance-ids
- Discover the occasion utilizing the next command:
- Delete the RDS occasion:
- Discover the occasion utilizing the next command:
aws rds describe-db-instances - Delete the occasion utilizing the next command:
aws rds delete-db-instances –db-instance-identifier
- Discover the occasion utilizing the next command:
- Delete the EMR Serverless software
- Discover the EMR Serverless software utilizing the next command:
aws emr-serverless list-applications - Delete the EMR Serverless software utilizing the next command:
aws emr-serverless delete-application –application-id
- Discover the EMR Serverless software utilizing the next command:
Conclusion
On this submit, we mentioned how EMR Serverless, as AWS managed serverless large information compute engine, integrates with well-liked OSS merchandise like TiDB and DolphinScheduler. We mentioned the best way to obtain information synchronization between TiDB and the AWS Cloud, and the best way to use DolphineScheduler to orchestrate EMR Serverless jobs.
Check out the answer with your personal use case, and share your suggestions within the feedback.
Concerning the Writer
 Shiyang Wei is Senior Options Architect at Amazon Net Providers. He’s specializing in cloud system structure and answer design for the monetary trade. Significantly, he centered on large information and machine studying functions in finance, in addition to the influence of regulatory compliance on cloud structure design within the monetary sector. He has over 10 years of expertise in information area improvement and architectural design.
Shiyang Wei is Senior Options Architect at Amazon Net Providers. He’s specializing in cloud system structure and answer design for the monetary trade. Significantly, he centered on large information and machine studying functions in finance, in addition to the influence of regulatory compliance on cloud structure design within the monetary sector. He has over 10 years of expertise in information area improvement and architectural design.

{kind=link}